|
|
The Design Axes |
|
| Home | Project Documentation | Mailing Lists | Site Map |
| Design Axes for Indian Language Computing | ||
|---|---|---|
| Prev | Next | |
Every solution to a problem functions in the context of an ``environment''. Viable design strategies are those that work with, and not against, the characteristics of the environment in which the designed solution has to function.
For example, in architecture (the brick-and-mortar kind), a good design strategy would be to use locally available building materials. This could be bamboo in one part of the world and compressed mud bricks in another. In contrast, a ``one size fits all'' design methodology that uses steel, cement and sheet glass is unlikely to be produce appropriate buildings for many places in the world.
As with physical architecture, the design of computing infrastructure also happens in the context of a surrounding social and physical environment. The characteristics of this environment dictate the core issues that have to be worked with in order to design usable, sustainable and economically feasible solutions.
To take two concrete examples, in developed societies, social structures are less feudal than those in India, and access to high-quality electric power is nearly ubiquitous. Computing originated in these developed societies, and so the basic building blocks of their computing infrastructure have been designed to work well in their environment. In the Indian context, we tend to use these same basic building blocks without significant change; it should not be surprising then, that the resulting solutions fail to make much headway.
Creating information processing products and services for the Indian subcontinent requires a designer to tackle a number of issues.
Power: high quality electric power is a scarce commodity in the Indian context. Our computing infrastructure needs to be designed accordingly.
Usability: user interfaces to our computing infrastructure need to be more intuitive to use.
Interoperability: interoperability between systems and applications is necessary for our computing infrastructure to be viable.
Locality of Information: Local, contextually relevant information has value--computing infrastructure that can gather and process contextually relevant information will provide value to its host society.
Value Addition: costs of labour and input materials in India differ from developed societies. Thus cost tradeoffs in the Indian context are different from those in developed societies. A computing device or service needs to be able to deliver value over and above that which is available by other more traditional means.
Social Structure: Indian society is feudal and stratified. These social conditions have some unique characteristics that need to be catered for when designing compute infrastructure.
Community/Ecosystem: designing compute infrastructure requires adequate attention to the rest of the ``ecology'' in which the system has to operate.
The rest of this section examines these issues in depth.
The availability of electric power forms the first hurdle to deploying compute infrastructure. Grid power supply tends to be intermittent and even when present tends to be delivered with voltages and frequencies that are out of specification. See Further Reading: Power for additional material on this topic.
The poor availability of power requires that the building blocks that would comprise Indian compute infrastructure be chosen carefully.
For example, the ubiquitous IBM PC clone consumes between 150 to 300 Watts of high-quality, 220 Volt AC power. Only a small portion (an estimated 1% or less) of the Indian population has access to electric power of this quality 24 hours a day.
The power needs of a piece of computing equipment can affect its potential market by orders of magnitude. Table 1 maps the estimated market reach (in terms of a percentage of the Indian population) to the power needs of a device.
Table 1. Power needs versus potential market size
| Device power requirement | Duration of usage | Possible energy sources | Maximum expected reach (percentage of population) | Comments |
|---|---|---|---|---|
| 1,000+ Watts | 24 hrs | Electric grid, with generator backup. | 0.01% | Data centers, urban offices etc. |
| 100--500 Watts | 8 hrs/daily | Grid supply with UPS and generator backup. | 0.1% | Typical PC with peripherals. Tied to the power outlet. |
| 10--50 Watts | 8--12 hrs/daily | Grid, solar or other power sources. | 1%-10% | Portable (but not necessarily mobile) computing devices, like village information kiosks. |
| 1 Watt | Intermittent use | Grid, solar or human power sources. | ~100% | Mobile, personal computing. |
As Table 1 indicates, the power consumption of a computing device has an inordinate influence on its potential reach and therefore on its social and market potential.
Indian compute infrastructure needs to be designed to work with the availability of power. Table: Typical Power Sources lists a few available power sources, and their characteristics.
Table 2. Typical Power sources
| Description | Power output | Comments |
|---|---|---|
| Human power: handheld generators | 1 to 5 Watts | Suited for intermittent operation. |
| Human power: pedal powered | Upto 40 Watts | Intermittent operation. |
| Solar photovoltaic | 1/10th Watt to 1 Kilowatt | Works only during the day. Battery backup adds cost and lowers reliability. |
| Animal powered | About 150 Watts | Intermittent operation. |
| Grid supply | 1KW or more | Not universally available. Plagued by problems of quality and availability. |
The issue of power availability would cease to be relevant if every rural or urban electrical consumer in India were to get high quality electric power. However, the ecological costs of providing 1+ KW of high quality electric power to each of India's citizens would be disastrously high. Designing compute infrastructure with a small power footprint is a much better alternative.
Currently, an affordable solar photovoltaic panel produces about 25 Watts of electric power. We thus need to develop compute devices that can work within this power budget.
Summary. The availability of electric power governs the reach of computing in the Indian context. Indian compute infrastructure needs to be built using devices that consume less than a few tens of watts of power and which can be powered by a variety of power sources.
Poor usability is the next hurdle to building a pervasive compute infrastructure for India. Existing methods of data entry are awkward and output methods are also immature. We look at these issues next, in Section 2.2.1 and Section 2.2.2 respectively.
The most common human-computer interface for western language input is a keyboard, modeled after the mechanical typewriters of the previous century. A computer keyboard is comprised of a number of keys (usually over a hundred) arranged according to a standard layout. Following typewriter conventions, these keys (mostly) correspond to the graphemes used by western scripts. Special forms such as the the Latin character 'c' combined with the cedilla (ç) are entered using special Compose key.
Keyboard based input is however, infeasible for devices with small form factors, such as PDAs and cell phones. For these devices, alternate input methods are used such as ``on-screen'' keyboards, voice recognition, handwriting recognition and overloading a numeric keypad for text input.
Designers have attempted to implement Indian script input using standard (western) computer keyboards. Due to the large number of graphemes in indian scripts, a one-to-one mapping between keyboard keys and the graphemes of a script is not feasible.
So keyboard input methods for Indic scripts usually follow one of two approaches: they either provide transliteration from roman text or use special layouts tailored to the script they support.
In transliteration schemes the user types phonetic input in Roman (English) notation which the system converts to indian language input.
This approach offers an easy learning curve for users who are already conversant with English text input. It however burdens a native speaker with the need to first learn the roman script to input his or her language.
Special keyboard layouts assign the keys of the keyboard to ``base'' elements of the script such as consonants and vowels. The system then translates a sequence of base consonants and vowels to the appropriate compound visual form.
While this approach frees a native speaker from having to first learn the roman script, it still remains non-intuitive. An added complication is the plethora of such keyboard layouts in use for each indic script. Figure 2 shows one of the many keyboard layouts for the Southern Indian language of Kannada.
Two major alternatives to keyboard based input methods for computers are handwriting recognition (gesture recognition) and voice recognition. Of these, voice recognition technology is still being researched and is not usable as a generic input method. Pen-based methods for western scripts are however, in production use.
India's poorer citizens learn to read and write their native scripts using a chalk and slate. A pen-like input device would provide an intuitive input interface that builds on basic skills. A pen-based input method would also be suitable for small form factor and low power computing devices like cell phones and personal digital assistants.
Practical implementations of pen based input methods for Indian scripts are not widely available.
Indian language input methods are discussed in depth in the Indic-Computing Handbook.
While several academic institutions in India have reported success with text to speech conversion for indian languages, audio output is useful only in specialized contexts. Visual displays remain the most popular way for presenting information to users.
Indian script display presents significant challenges to an implementor:
First, indic scripts are complex to render; while the general direction of rendering is left-to-right, the visual elements of these scripts are laid out in a two-dimensional manner in the general case (i.e., left, right, above and below a reference point). The process of transforming a series of character codes into visual form is a complex one.
Second, indic scripts need a larger number of pixels per grapheme than typical western scripts to be readable; the 7x14 or 8x16 pixel average dimensions used for Latin scripts are insufficient. This affects small devices with limited display sizes.
Since Indic rendering is complicated, some applications and indian language websites have chosen to work directly with visual layout and application-specific fonts. Such font-specific approaches suffer from problems of poor data interoperability.
Summary. Existing computing devices do not offer an easy to use experience for Indian language users. Keyboard input is awkward and the complexities of rendering Indian scripts have led to the deployment of many ad-hoc solutions.
Data is truly valuable when it can be seamlessly shared; interoperability is essential to the success of a compute infrastructure. Such interoperability can only be achieved over the foundation of standards that components of the compute infrastructure adhere to.
We have two broad kinds of standards that underlie interoperability:
Character set standards define the mapping between the ``characters'' of a language and the digital bit patterns used to represent them. For example, the characters of US English are encoded using the character set standard known as ASCII (American Standard Code for Information Interchange).
For Indian scripts, the national standard, ISCII (Indian Standard Code for Information Interchange) covers the major scripts in use in India. These scripts are also covered by Unicode standard.
However, many regional linguistic groups have formulated their own character set standards for their own use; for example, TSCII for Tamil, KSCLP for Kannada among others. In addition, some popular applications use their own application-specific encoding schemes. The profusion of character encodings makes the process of reliably processing indian language data complicated.
Standards are similarly needed for data formats and for communication protocols. For a truly pervasive compute infrastructure, documented and open protocols and formats need to be used in preference to proprietary ones.
Summary. Ensuring interoperability between the component parts of the Indian compute infrastructure is a big challenge.
Information systems in India today are structurally oriented towards disseminating information generated by a small number of sources of information. Information flow is mostly one-way: from the information sources like news agencies, corporations and government agencies to the consumer (for example, this is the way television and the print media work). Distributed systems that enable every citizen to be a potential information source do not exist.
Yet, there is a lot of local information that has value in-context. Tapping this information would open up entirely new markets.
The key characteristic of local information is that it is local both in content and value; for example, the rainfall pattern in East Bihar would be of little relevance to a farmer in Maharashtra.
Such local information is best collected and disseminated by local communities themselves. For example, information collection centers at agricultural centers, which record and publish prices and sales volumes of agricultural produce would be of value to the farmers of the neighboring villages.
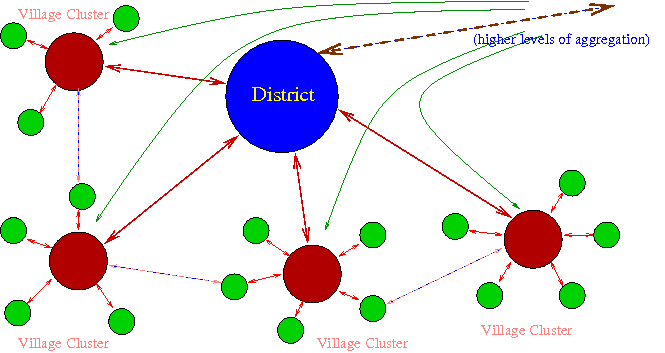
Figure 3 represents schematically how local information could be aggregated and processed. Some information could be aggregated at the village level, and some would make sense only at higher levels of aggregation. The figure attempts to show the information flow between villages, clusters of villages, districts and higher levels of aggregation.
Summary. Compute infrastructure serving the indian subcontinent should make it easy to the collect and disseminate local information. Every Indian citizen could then become an active contributor and participant in the information ecosystem.
The proposed compute infrastructure should offer to its users significant value when compared to its fixed and operational costs.
There have been some efforts in reducing the cost of computing hardware for the Indian context: for example, Emergic Solutions has attempted to produce a stripped down PC costing about INR 5000 (about one-sixth the current entry level price for a full featured PC). The Simputer design attempts to spread the cost of the device across multiple users, by allowing per-user data to be stored on a cheap smart card.
However, just lowering the cost of the computing device is not enough. In the end, the adoption of a computing device in the market is determined by the value provided by it to the end-user, and not just by the devices cost. Being able to provide value in this manner requires the complete system to be workable in the Indian context; for example, we would need low-power computing, systems for the dissemination of local information and easy to use computing devices.
Summary. Computing infrastructure needs to be designed in a way that adds value to the context where it is being deployed.
A successful compute infrastructure would need to work harmoniously in the society that it serves. For example, a society that places a strong emphasis on individual achievement and individual possession of material artifacts would choose to emphasise personal ownership of compute hardware. Other societies may be more open to sharing; In such societies, a design that lowers per-user cost of information access by allowing multiple users to share a computing device may be workable.
Indian society is feudal in nature; and in rural parts of India is usually highly segregated. In Indian society, the resources a person has access to is largely determined by his or her birth.
|
Social structures in a typical Indian village Most villages in India are segregated along lines of caste. Figure 4 shows the layout of a village in south india that the author visited in 1995. The prime part of the village was occupied by the Naidu community, a caste of landowners. The next area comprised residences of washer-folk and other castes who served the Naidu community. The regions where the people even lower down in the caste hierarchy resided were further down the village road. The ``untouchables'' lived separated from the main village by about half a kilometer. This was the cleanest and best-maintained part of the village even though the people here lived in conditions of great economic hardship. On the economic front, the landowners controlled the economy of the village. Land ownership was confined to the upper castes, while the lower castes eked their living by selling their labour. Payment to the lower castes was rarely in cash, and was instead given in the form of foodstuffs, paid once a year. There were numerous social restrictions on the lower castes: lower caste people were not permitted to enter the upper caste areas freely, on the pain of physical punishment. Lower caste men were required to step off the road if an upper caste person was using it. Lower caste children were allowed into the nearby school (not shown in the figure), but had to sit on the floor at the sides of the class room; the benches were for the use of upper-caste children. Girl children who reached puberty were not permitted to continue schooling, irrespective of their community of birth. There was one bore well in the village that supplied drinking water, which the lower castes were forbidden to use. The untouchables had their own (open) well. |
Some of the social characteristics that the compute infrastructure needs to surmount are summarized in the sidebar Social structures in a typical Indian village: the segregation of society along caste lines, separation of living areas, economic inequity, and the determination of a human being's potential for growth on the basis of her birth caste.
Compute infrastructure designed for the Indian context needs to be resistant to being controlled at a few ``choke-points'' if it has to reach out to, and provide hope to, all of India's citizens. Two concrete examples are used to illustrate this idea.
Digital identities would be needed for the system to verify the authenticity of participants in certain kinds of transactions.
A distributed ``peer to peer'' architecture, would relatively immune to social and economic hurdles being placed in the way of being an inclusive technology. It would thus be preferable to a centralized hierarchy of certifying authorities.
The typical indian village is organized so that some parts are ``off bounds'' for the lower castes. The location of information access points can determine the ease with which communities can participate in the information ecosystem.
Technology that allows access to information without physical restraints (for example, wireless networking) is therefore preferable to one that requires physical tethers.
Summary. To be able achieve its full potential, Indian compute infrastructure needs to be designed to work in the presence of restrictive social structures.
Software development for the compute infrastructure would need the following to be viable:
An accepted vocabulary for describing the technical aspects of requirements and implementations.
Knowledge and ``folklore'' about the implementation issues faced by developers writing Indian language software should be widely available and should cover every Indian language in a manner understandable to software developers unfamiliar with the language.
Forums where developers can gather to discuss issues about standards or implementation techniques related to Indian language computing.
Once these basics are in place, commercial and open-source software development for the compute infrastructure can happen in an efficient manner. Section 4 describes the steps that the Indic-Computing project is taking in this regard.
Summary. A vibrant software developer community that is well supported by the necessary information and software development practices is necessary for pervasive Indian language computing to become a reality.
| Prev | Home | Next |
| Design Axes for Indian Language Computing | Analyses |
This, and other project documentation, can be downloaded from [ http://indic-computing.sourceforge.net/documentation.html ].
|
Copyright © 2001--2009 The Indic-Computing Project. Contact: jkoshy |
View document revision history |