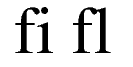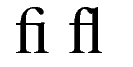|
|
Tutorial: Computers and Indian Languages |
|
| Home | Project Documentation | Mailing Lists | Site Map |
Caution: This tutorial is in the process of being rewritten and revised. It has been published on our site to facilitate reviews--it is not yet at a stage where it is ready for public consumption. Please pardon the errors and please help us improve the tutorial.
In this tutorial we will take a peek ``under the hood'' and examine how computers actually process text. We will talk about character encodings, input methods, fonts, locales and many other things that the casual user is not aware of when using computers.
However, these concepts are very important for software developers wanting to add support for new languages to computers.
This tutorial covers the basics; the special issues that come up when processing Indian scripts and languages get detailed coverage in other parts of the Handbook.
After reading and digesting this tutorial, you should be able to:
Understand how computers process text and know what the term character set means.
Understand the importance of standard character set encodings for data exchange.
Be able to distinguish between fonts and glyphs, character set encodings and font encodings.
Know what the terms code point, code page, character set and character set encoding mean, and how they differ from each other.
Understand what an input method is, and be able to describe a few common input methods.
After reading and digesting this tutorial you will be in a position to use the rest of the material in this Handbook in an effective manner.
The tutorial is organized as follows:
Section 2.1 introduces you to the kinds of processing that computers do on text.
Section 2.2 covers the basic issues involved in representing a human language on a computer. It introduces you to the concept of character sets shows how character sets can be encoded for processing by a computer.
Section 2.4 examines the way humans and computers interact. We discuss the ways data is input to a computer and how data is presented human consumption.
Section 2.3 covers the basics of fonts and font technologies.
Section 2.5 covers the basics of program customization for different regions and cultural traditions.
Computers are introduced to neophytes as ``number crunching machines'', as devices related to the ancient abacus, only more electronic. Yet, for the most part, the modern computer spends an insignificant portion of its time doing numeric calculation. Instead, the great utility of computers comes from the fact that they are excellent symbol manipulation machines.
To a computer, human readable text is merely a sequence of symbols; symbols that it can process and transform at blinding speed, in the precise manner written down in the software program that it is executing.
Here is a list of a few typical text transformation processes that computers are called on to do:
They render text into readable ``characters'' either on a display device or onto a printed page. We expect computers to do this correctly, taking into account complex typographical features like ligatures and context dependent rendering (see the sidebar Ligatures and context dependent rendering).
We expect the computer to be able to change the rendered appearance of the text: for example, we may want a particular part of the displayed text to be rendered with a different weight (bold, medium, etc.) or with a different font entirely.
Computers take in input from a keyboard or other input device. For some scripts and languages this process is straightforward: a user would type at a keyboard that possesses one key per ``character'' of the script.
However, some scripts are so complex that this simple approach is out of the question. Indic and Far-Eastern scripts require the computer to give considerable assistance to the user keying in data. For example, Kanji (Chinese and Japanese) ideograms are input by requiring the user to select the required character from thousands of alternatives.
Computers are expected to assist in the process of selection and editing portions of the displayed text.
The end-user expects this process to be straightforward; in typical graphical user interfaces regions of text are manipulated using mouse gestures (clicking, dragging etc).
However, the process of mapping between the display and the underlying characters is not straightforward for some scripts. The Indic scripts, for example, use a visual ordering that is different from the manner text is represented internally in the computer. For such scripts the mapping between the internal representation and the visual presentation can be quite complex.
Computers are expected to know how to determine what constitutes a ``word'', a ``sentence'', a ``stanza'' or ``paragraph'' in the text.
We expect the computer to be able to analyze the morphological structure of text: for example, extract word roots, stems and suffixes, perform grammar checks on sentences and the like.
This requirement implies that the controlling software needs to know about the linguistic properties of the text elements that it is manipulating.
Similarly, we expect software to be able to break lines correctly, and to hyphenate words correctly.
Some languages like Sanskrit, when written using the Devanagari script tend to have very long ``words''. For such scripts, the rules that determine where a word can be hyphenated can be quite complex (see Figure 2-1).
Computers are expected to easily sort, filter, and search in textual data; indeed much of the value of information technology comes from the ability of computers to do these tasks well.
These functions are not always easy to implement correctly as some scripts in use in the world today have multiple conflicting ways of being represented inside the computer.
Computers are expected to be able to compress text or otherwise prepare it for transmission, archival and other kinds of processing. Further we expect to be able to recover the original text from the transformed version without error.
Clearly, these diverse tasks are possible only if the underlying software architecture has been designed to enable these in the first place. In subsequent sections of this tutorial we will examine the foundations over which computer processing of text is built.
This, and other project documentation, can be downloaded from [ http://indic-computing.sourceforge.net/documentation.html ].
|
Copyright © 2001--2009 The Indic-Computing Project. Contact: jkoshy |
View document revision history |